Topology ConsiderationsFor jobs in which a particular node geometry is desired please open a ticket with help+bw@ncsa.illinois.edu to work with the resource admins in setting up a reserved block of nodes with a particular geometry that can be used with the following methods below. Computational processes run within jobs on Blue Waters are typically multi-rank MPI jobs run with the aprun command. Aprun instantiates a specified number of application instances (MPI calls them ranks, Cray calls them PE's in their documentation) on the available integer cores assigned to the job. Which CPU cores have ranks instantiated on them and how the ranks are ordered among the array of cores is under control of the user. The application ranks communicate with one another, defining the application's communication topology. The order that the MPI ranks are placed on its execution cores map the application's topology onto its execution cores. The closer the topology of the application matches the topology of the cores doing the computing, the more efficient the application's communication will be. The user can choose from among pre-defined rank order sets, or with more knowledge of the application's topology, can use a custom rank order to increase the application's communication efficiency. Placing Application Ranks On Execution CoresWhich CPU cores receive ranks is set by the -cc and -d options of aprun; see the aprun manpage for details. Using -cc specifiies explicitly which cores to use, -d tells aprun to reserve that many cores per instantiated rank. Each XE node on Blue Waters has 32 integer (execution) cores, each XK node has 16 cores. Each consecutive even-odd pair of integer cores belong to one Bulldozer module, so they have separate execution pipelines but share other resources. Cores 0 and 1 are on the same bulldozer module, likewise 2 & 3, 4 and 5, and so on. If you run fewer than 32 ranks per node, your application will most likely perform better using -d 2 with your aprun command so that only one rank will run per bulldozer module. Using Pre-Defined Rank OrdersRank order within the eligible CPU cores depends on the value of the MPICH_RANK_REORDER_METHOD environment variable. The default method is the SMP-Style Rank Ordering. In brief: Round-Robin Rank Ordering MPICH_RANK_REORDER_METHOD=0 is "round robin" ordering. The first rank is on the first node, the second rank is on the next node, and so on, until all nodes have one rank, then the next rank after that is on the next available core on the first node. If I have a job on 4 nodes and I want to run 14 ranks, placement is: first node: rank 0, 4, 8, and 12; second node: rank 1, 5, 9, and 13; third node: rank 2, 6, and 10, and fourth node: ranks 3, 7, and 11.
SMP-Style Rank Ordering MPICH_RANK_REORDER_METHOD=1 is "SMP style" ordering. Ranks are placed consecutively until the node is filled up, then on to the next node. If again I had a job with 4 nodes and placed 6 ranks on them (and I set either -cc or -d such that only 4 ranks would fit on a node): first node would have ranks 0, 1, 2, and 3; second node would have ranks 4, 5, 6, and 7; the third node has ranks 8, 9, 10, 11; and the fourth node has rank 12 and 13. This is the most common option and is the default on Blue Waters if no MPICH_RANK_REORDER_METHOD is set.
Folded Rank Ordering MPICH_RANK_REORDER_METHOD=2 is "folded" rank ordering. Ranks are populated down the node list like MPICH_RANK_REORDER_METHOD=0 but then the next ranks are populated back up the node list in reverse order. Using this order with 4 nodes and 14 ranks gives: first node has ranks 0, 7, and 8; second node has ranks 1, 6, and 9; fourth node has 2, 5, 10, and 13; the fourth node has ranks 3, 4, 11, and 12.
Custom Rank Ordering (From A File) MPICH_RANK_REORDER_METHOD=3 this is a custom rank order, read from the file in the current directory with name MPICH_RANK_ORDER (this is a static file name, not an environment variable). The use of all MPI-related environment variables including MPICH_RANK_REORDER_METHOD is documented in detail on the system in the intro_mpi man page. That is the definitive documentation from Cray of these features on Blue Waters. Using PerfTools to Discern Communication TopologyThe Cray "perftools" package has software tools to instrument code and print out functional usage, performance data and other information. If you use it to analyze the communcation patterns of an application, you can ask the pat_report tool to print out a suggested rank order file based on the communcations it saw during the instrumented run. How to use perftools is documented here: https://bluewaters.ncsa.illinois.edu/cpmat. Using the following options will get pat_report to output a suggested rank order file: pat_report ... -O ...
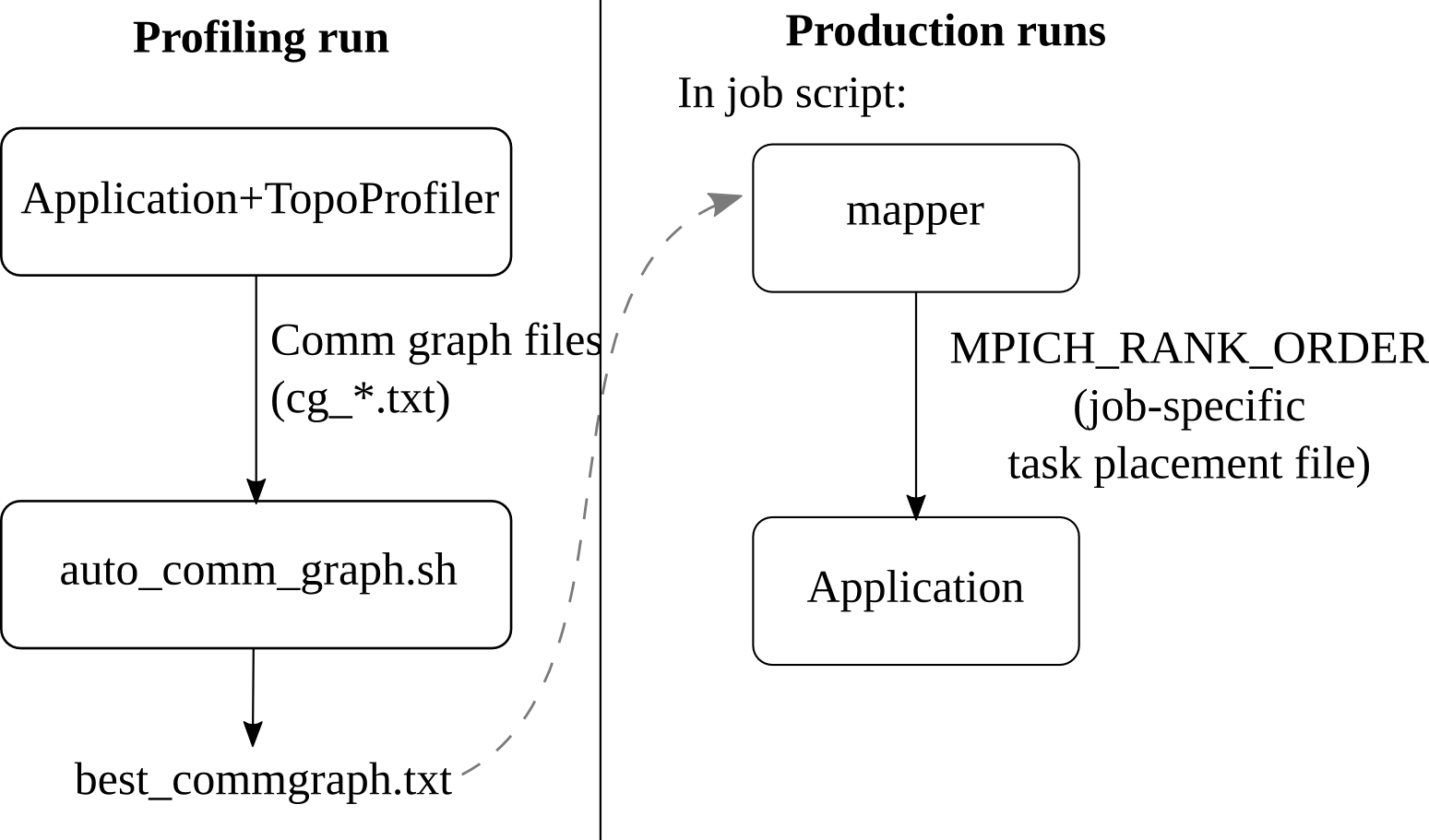
mpi_sm_rank_order Please see the pat_build man page for details (you must "module load perftools" to have access to the man page). An example of doing this might look like (app MUST be built with perftools already loaded): $ cd my_code_dir $ module load perftools $ make ..... compilation successful. New executable generated: my_parallel_app $ pat_build -g mpi -O apa my_parallel_app ... (this generates my_parallel_app.pat) $ cp my_parallel_app.pat /scratch/sciteam/myusername $ cd /scratch/sciteam/myusername $ qsub my_parallel_run_script.bash job 12345 submitted .... (app runs) $ cd /scratch/sciteam/myusername $ module load perftools $ pat_report -O mpi_rank_order -o new_analysis_output_text_file.out ./complicated_directory.12345 (pat_report now does its thing. new_analysis_output_text_file.out contains its general output, and there will be a suggested custom order file in the directory that you can use for your next run.) Generating a Custom Rank Order From A Known Communication TopologyIf you specifically know the underlying topology of your application, Cray supplies a tool as a part of the perftools package that will create a rank order customized that topology. The tool is in the perftools module on the system, so you must run "module load perftools". You can then run the grid_order command to output an appropriate MPICH_RANK_ORDER file that will (hopefully) arrange nodes to best take advantage of that communication pattern. Run "man grid_order" to get the specifics of how to do this (you must have the perftools module loaded to see the man page). TopoMappingTopoMapping is a utility developed by the Parallel Programming Laboratory (PPL) of Prof. Sanjay Kale. To get started with TopoMapping, see the /sw/bw/topomapping/README.txt file on the system and load the topomapping module (after unloading darshan). This is an overview of the process documented in the README.txt file.
The details of TopoMapping is avaiable in the developers paper titles "Automatic Topology Mapping of Diverse Large-scale Parallel Applications". |
Skip to Content



Blue Waters User Portal
Sign In

Blue Waters is supported by the National Science Foundation (awards OCI-0725070 and ACI-1238993) the State of Illinois, and the National Geospatial-Intelligence Agency.
Contact Blue Waters Team with questions regarding this page.
Copyright 2024 Board of Trustees of the University of Illinois. All rights reserved. Web privacy notice.