IO Considerations
IO best practices include balancing between file size and number of files, evaluating the use of Lustre striping, using subdirectories to avoid puting a large amout of files in one directory, and exploring IO strategies through the use of HDF5, NetCDF, etc.
When writing, consider avoiding the creation of hundreds of thousands of small files, as well as the creation of a single large file. One file per node is often a good starting point; When reading, avoid reading in hundreds of thousands of files, as well as having all processes read the same file (unless your application is using a parallel IO library).
Look into file striping also, which distributes a single file to multiple OSTs--allowing file size to grow to the combined size of the chosen number of OSTs rather than a single server. Striping increases bandwidth for parallel IO.
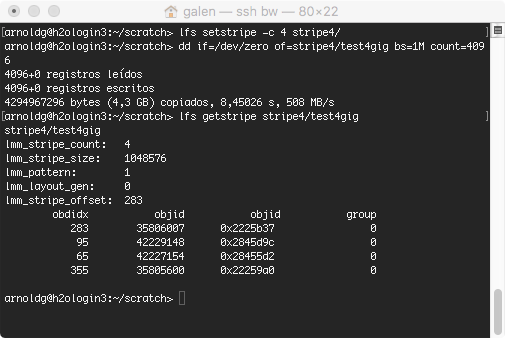
lfs is the lustre utiliy for viewing and setting file striping information, with stripe count for the number of OSTs for a file, stripe size the block size a file will be broken into, and stripe offset the ID of an initial OST for Lustre. Refer to the lfs man page for more information. The default stripe count is set to 1 on Blue Waters.
Two main factors for increasing the default stripe count are:
If the application I/O is:
keep the default striping of 1, or use no more than 4 for large file support. Setting the stripe count large for non-parallel I/O will degrade your I/O performance. If the motivation for striping is only that the file(s) are very large ( > 100 GB ) and the I/O is not parallel, consider setting the stripe count to 2 or 4. Remember, lfs setstripe on a directory will cause new files and directories under it to inherit the striping :
References: |
Skip to Content



Blue Waters User Portal
Sign In

Blue Waters is supported by the National Science Foundation (awards OCI-0725070 and ACI-1238993) the State of Illinois, and the National Geospatial-Intelligence Agency.
Contact Blue Waters Team with questions regarding this page.
Copyright 2024 Board of Trustees of the University of Illinois. All rights reserved. Web privacy notice.