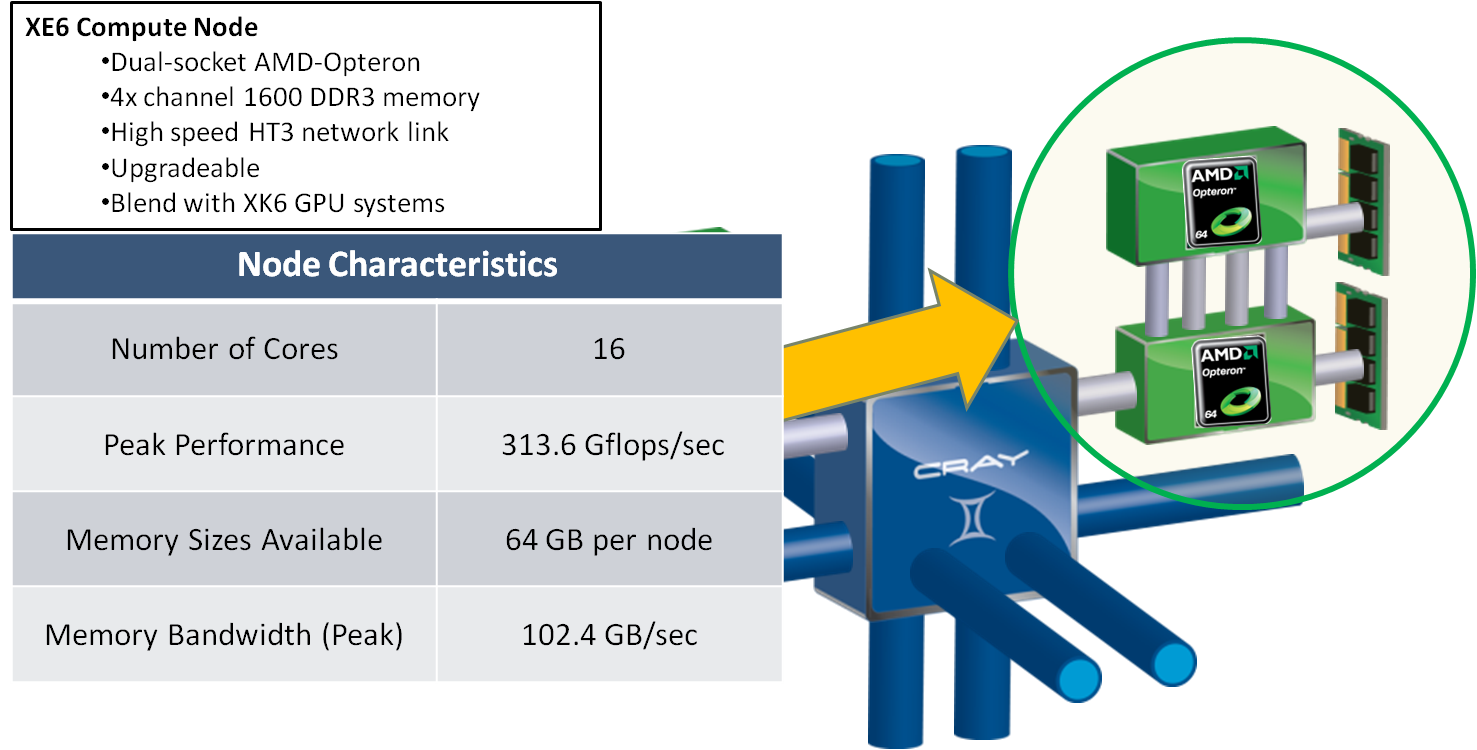
Brief Blue Waters System OverviewBlue WatersBlue Waters is a Cray XE6/XK7 system consisting of more than 22,500 XE6 compute nodes (each containing two AMD Interlagos processors) augmented by more than 4200 XK7 compute nodes (each containing one AMD Interlagos processor and one NVIDIA GK110 "Kepler" accelerator) in a single Gemini interconnection fabric. This configuration enables extremely large simulations on hundreds of thousands of traditional CPUs for science and engineering discovery, while also supporting development and optimization of cutting-edge applications capable of leveraging the compute power of thousands of GPUs. Blue Waters NodesBlue Waters is equipped with three node types: traditional compute nodes (XE6), accelerated compute nodes (XK7), and service nodes. Each node type is introduced below. Traditional Compute Nodes (XE6) The XE6 dual-socket nodes are populated with 2 AMD Interlagos model 6276 CPU processors (one per socket) with a nominal clock speed of at least 2.3 GHz and 64 GB of physical memory. The Interlagos architecture employs the AMD Bulldozer core design in which two integer cores share a single floating point unit. In describing Blue Waters, we refer to the Bulldozer compute unit as a single compute "core" and consider the Interlagos processors as having 8 (floating point) cores each, although this processor has been described elsewhere as having 16 cores. The Bulldozer core has 16KB/64KB data/instruction L1 caches, 2 MB shared L2 and instruction support for SSSE3, SSE4.1, SSE4.2, AES-NI, PCLMULQDQ , AVX, XOP, and FMA4. Each core is able to complete up to 8 floating point operations per cycle. The architecture supports 8 cores per socket with two dies, each die containing 4 cores forming a NUMA domain. The 4 cores of a NUMA domain share an 8 MB L3 cache. Access times for shared memory on the other die in the same socket are somewhat longer than access times within the same die. See chapters 1 and 2 in the AMD document Software Optimization Guide for AMD Family 15hProcessors for additional technical information on the 62xx processor.
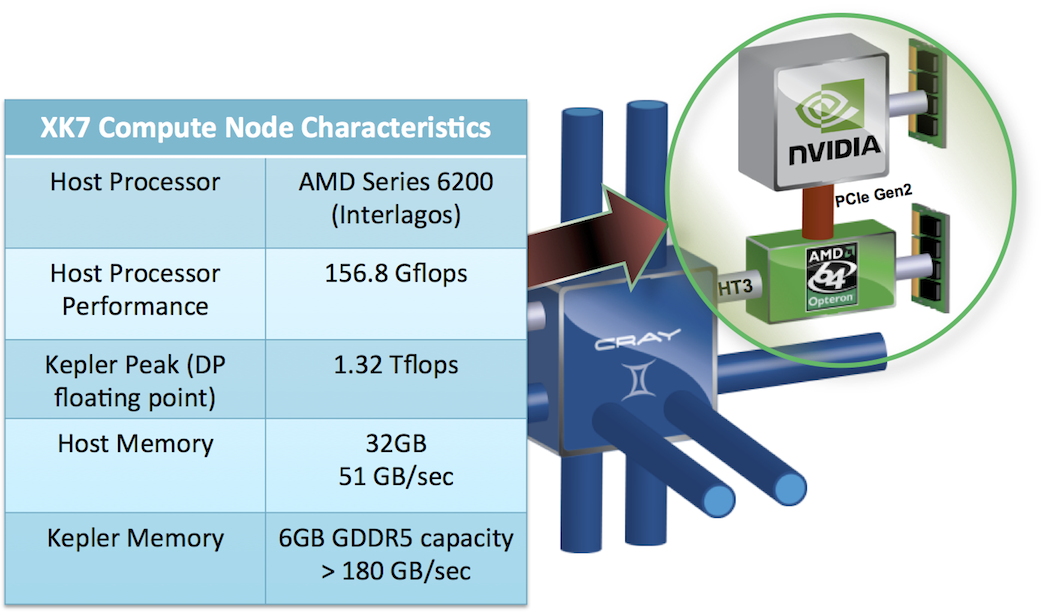
GPU-enabled Compute Nodes (XK7) Accelerator nodes are equipped with one Interlagos model 6276 CPU processor and one NVIDIA GK110 "Kepler" accelerator K20X. The CPU acts as a host processor to the accelerator. Currently the NVIDIA accelerator will not directly interact with the Gemini interconnect so that data needs to be moved to a node containing an accelerator, and that data may be accessed by the accelerator as mapped memory, or through DMA transfers to accelerator device memory. Each XK7 node has 32 GB of system memory while the accelarator has 6 GB of memory. The Kepler GK110 implementation includes 14 Streaming Multiprocessor (SMX) units and six 64?bit memory controllers. Each of the SMX units feature 192 single?precision CUDA cores. The Kepler architecture supports a unified memory request path for loads and stores, with an L1 cache per SMX multiprocessor. Each SMX has 64 KB of on-chip memory that can be configured as 48 KB of Shared memory with 16 KB of L1 cache, or as 16 KB of shared memory with 48 KB of L1 cache. The Kepler also features 1536KB of dedicated L2 cache memory. Single-Error Correct Double-Error Detect (SECDED) ECC code is enabled by default.
The Cray XK currently supports exclusive mode for access to the accelerator. NVIDIA's Proxy (part of "Hyper-Q") manages access for other contexts or multiple tasks of the user application via the CRAY_CUDA_MPS (formerly CRAY_CUDA_PROXY) environment setting. Each Cray XE6/XK6 XIO blade contains four service nodes. Service nodes use AMD Opteron "Istanbul" six-core processors, with 16 GB of DDR2 memory, and the same Gemini interconnect processors as compute nodes. XIO nodes take one of four roles as Service nodes:
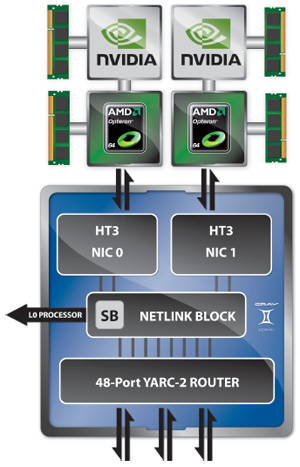
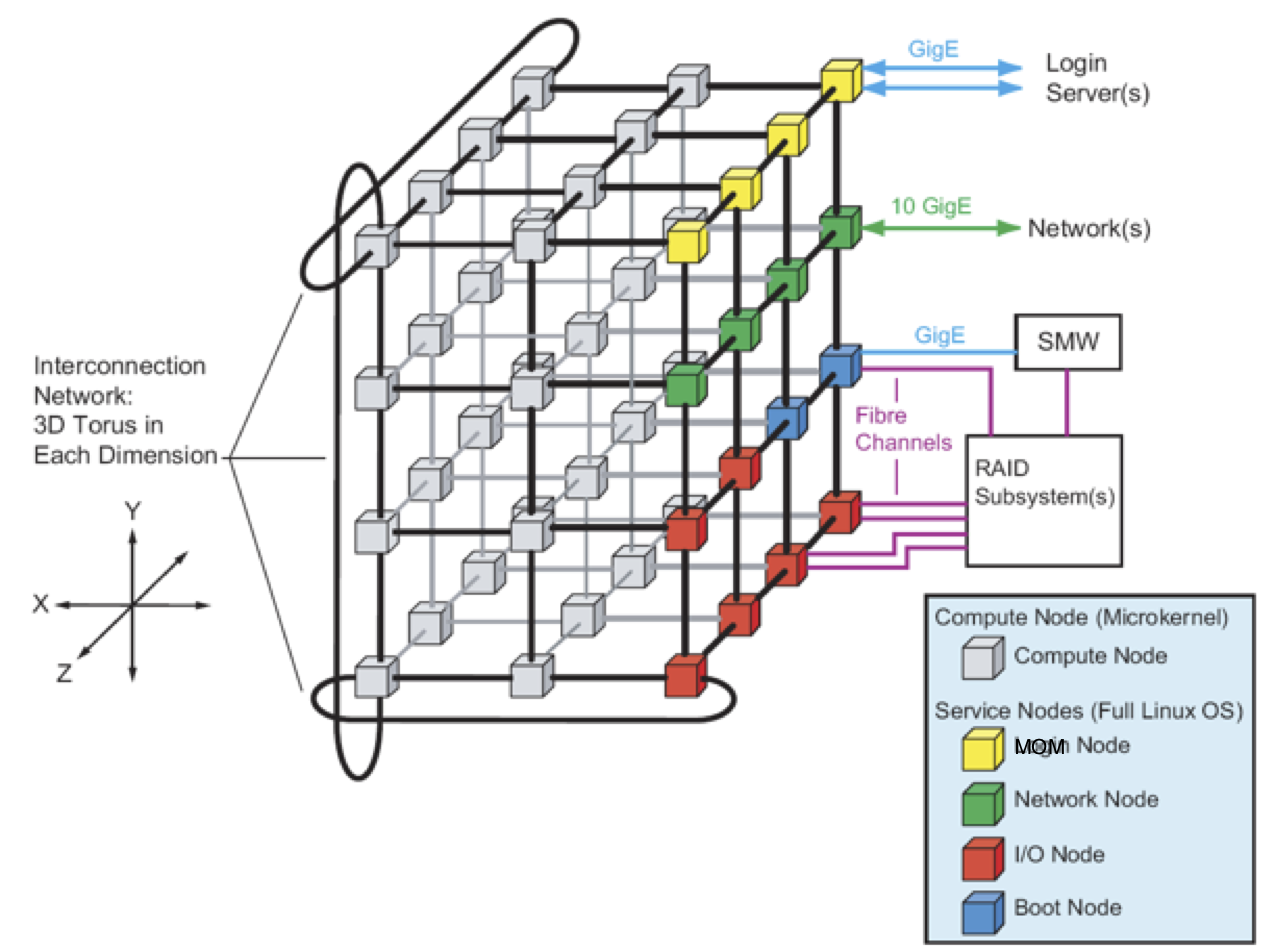
InterconnectThe Blue Waters system employs the Cray Gemini interconnect, which implements a 3D torus topology. Note that there are 2 compute nodes per gemini hub. The torus is periodic or re-entrant in all directions (paths wrap around). A schematic of the general use of the high speed network (HSN) is shown in the following figure detailing a simplified view of the location of all node types in the torus. In reality the IO and service nodes are not confined to a single "plane" in the torus.
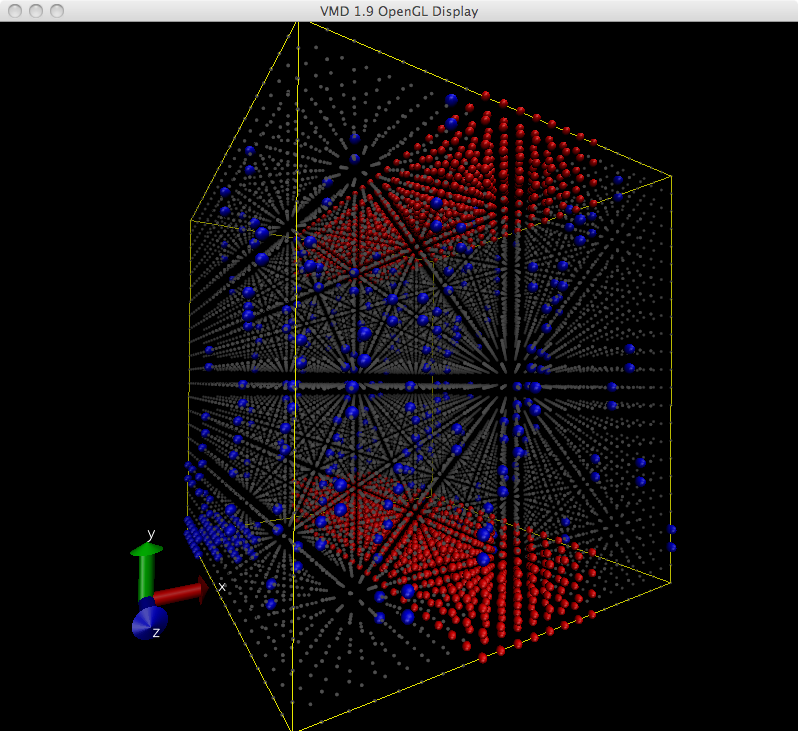
The (x,y,z) locations of the Gemini routers can be plotted to show a particular view of the torus. In the image below the Blue Waters torus is shown with gray dots representing the location of XE nodes, red spheres representing the location of XK nodes and blue spheres representing service nodes. Note that the system should be viewed as periodic or re-entrant and that there is no unique origin and no corners in a torus.
The native messaging protocol for the interconnect is Cray's Generic Network Interface (GNI). A second messaging protocol, the Distributed Shared Memory Application (DMAPP) interface, is also supported. GNI and DMAPP provide low-level communication services to user-space software. GNI directly exposes the communications capabilities of the Gemini while DMAPP supports a logically shared, distributed memory (DM) programming model and provides remote memory access (RMA) between processes within a job in a one-sided manner. For more information please see the Using the GNI and DMAPP APIs document. Data StorageBlue Waters provides three different file systems built with the Lustre file system technology. The three file systems are provided to the users as follows:
All three file systems on Blue Waters are built using Cray Sonexion 1600 Lustre appliances. The Cray Sonexion 1600 appliances provide the basic storage building block for the Blue Waters I/O architecture and are referred to as a "Scalable Storage Unit" (SSU). Each SSU is RAID protected and is capable of providing up to 5.35 GB/s of IO performance and ~120TB of usable disk space. The /u and /projects are configured with 18 (eighteen) SSUs each, to provide 2 PB usable storage and 96 GB/s IO performance. The /scratch file system uses 180 (one hundred eighty) SSUs to provide 21.6PB of usable disk storage and 963 GB/s IO performance. This file system can provide storage for up to 2 million file system objects. Permissions for Blue Waters uses a one-time password system for logging into accounts based on Duo Moble. You will need to either install the Duo app on a smart phone or request a Duo hardtoken during the identity creation process. . Queues and quotas discussed in the User Guide. Compiling and LinkingThe Blue Waters development environment include four compiler suites:
The default programming environment is the Cray ( The programming environments provide wrappers for compiling Fortran (ftn), C (cc), or C++ (CC) programs, so that similar compiler commands can be used no matter which compiler environment is selected. These wrapper scripts also check for the presense of other loaded modules and take the appropriate measures to add include paths and libraries with compiling and linking. See the Compiling page in the User Guide for more information. ReferenceLinks to Cray, AMD, Nvidia & compiler vendor developer sites with a list of recommended reading:
|
Skip to Content



Blue Waters User Portal
Sign In

Blue Waters is supported by the National Science Foundation (awards OCI-0725070 and ACI-1238993) the State of Illinois, and the National Geospatial-Intelligence Agency.
Contact Blue Waters Team with questions regarding this page.
Copyright 2024 Board of Trustees of the University of Illinois. All rights reserved. Web privacy notice.