TAU (Tuning and Analysis Utilities)TAU is not currently supported on Blue Waters. Please use CrayPAT for profiling. DescriptionTAU Performance Systems is a portable profiling and tracing toolkit for performance analysis of parallel programs written in Fortran, C, C++, Java, and Python. TAU (Tuning and Analysis Utilities) is capable of gathering performance information through instrumentation of functions, methods, basic blocks, and statements. TAU's profile visualization tool, paraprof, provides graphical displays of the performance analysis results, to help the user visualize the collected data. How to use TAU
ExamplesThe instrumentation method:
The "tau_exec" method:
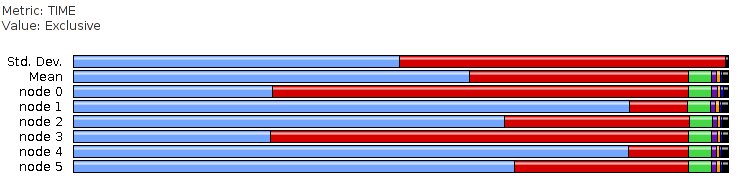
For both methods, to view the profile results, either run TAU's "pprof" in the directory containing the profile.* files to see a text-format output, or pack, transfer to a local machine, unpack, and use TAU's "paraprof" (a Java program) to visualize: paraprof --pack results.ppk scp to a local machine. On the local machine, paraprof --dump results.ppk paraprof Two sample ParaProf screen snapshots are below. Profiling results on all MPI ranks:
Profiling results of MPI rank 1:
Additional Information / References
AcknowledgementThanks a lot
|
Skip to Content



Blue Waters User Portal
Sign In


Blue Waters is supported by the National Science Foundation (awards OCI-0725070 and ACI-1238993) the State of Illinois, and the National Geospatial-Intelligence Agency.
Contact Blue Waters Team with questions regarding this page.
Copyright 2024 Board of Trustees of the University of Illinois. All rights reserved. Web privacy notice.