Using Cray Reveal and scoping loops for OpenMPDescriptionThe latest Cray perftools module and new Reveal anaylsis tool can be used to automatically markup loops for OpenMP parallelization. Reveal will do the variable scoping and create directives with the appropriate private and shared clauses for loops you choose to target. While the tool is semi-automatic and still requires programmer input, it is helpful at detecting which variables may safely be used privately and which must be shared to ensure algorithm correctness. How to use Reveal to scope loops
Add the usual flags to run with perftools to your compile and link commands for your Makefile or build process (if present, drop -g as it interferes with Cray profiling):
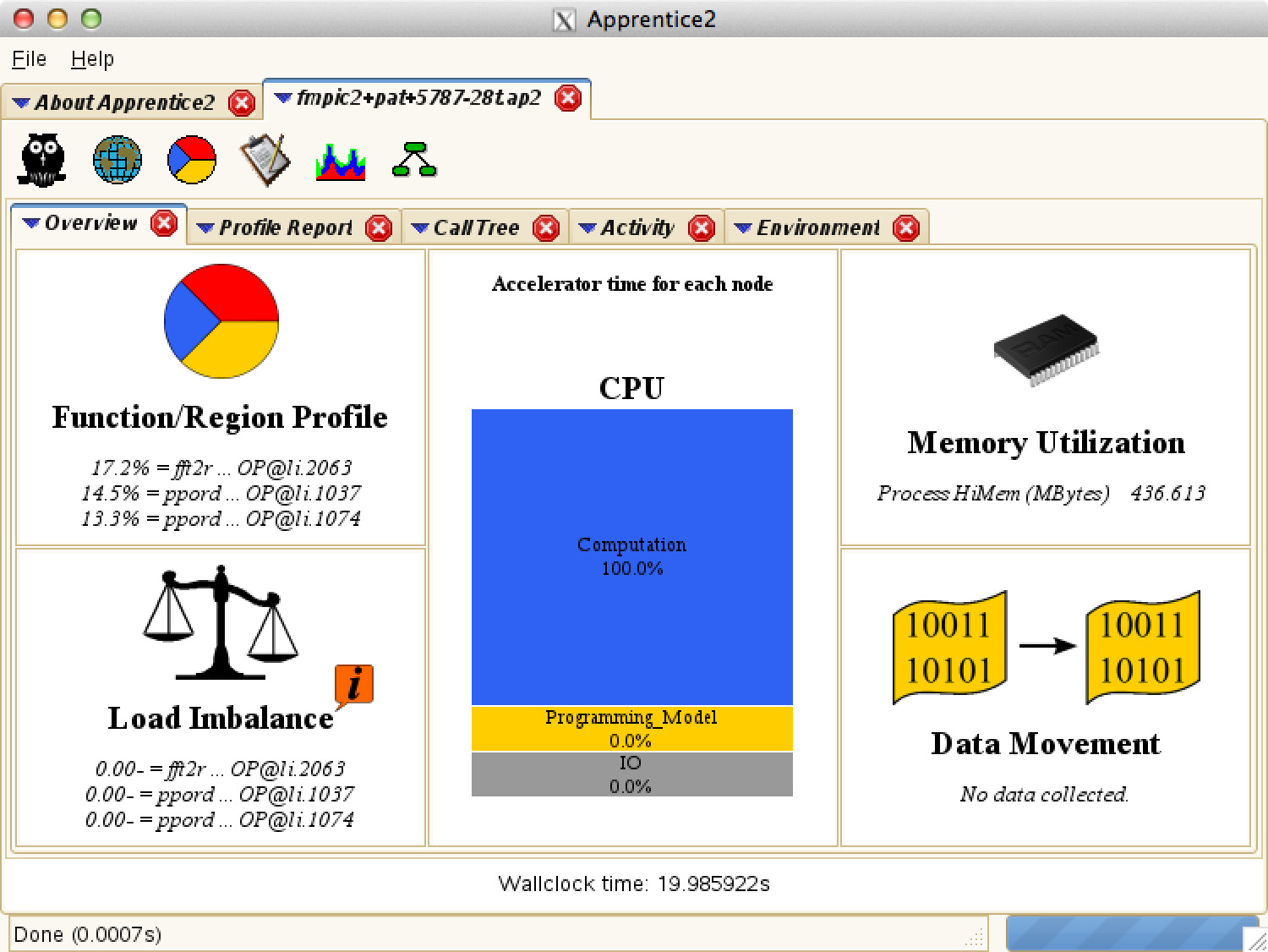
Instrument the code and run the instrumented version, and then process the .xf file for apprentice 2:
At this point, the reveal tool can be used with the application and perftools to do some OpenMP analysis. You can use the profile info at this step as well. Rebuild the application with flags similar to those below -- creating a program library (use a full path to your program library with multi-directory builds):
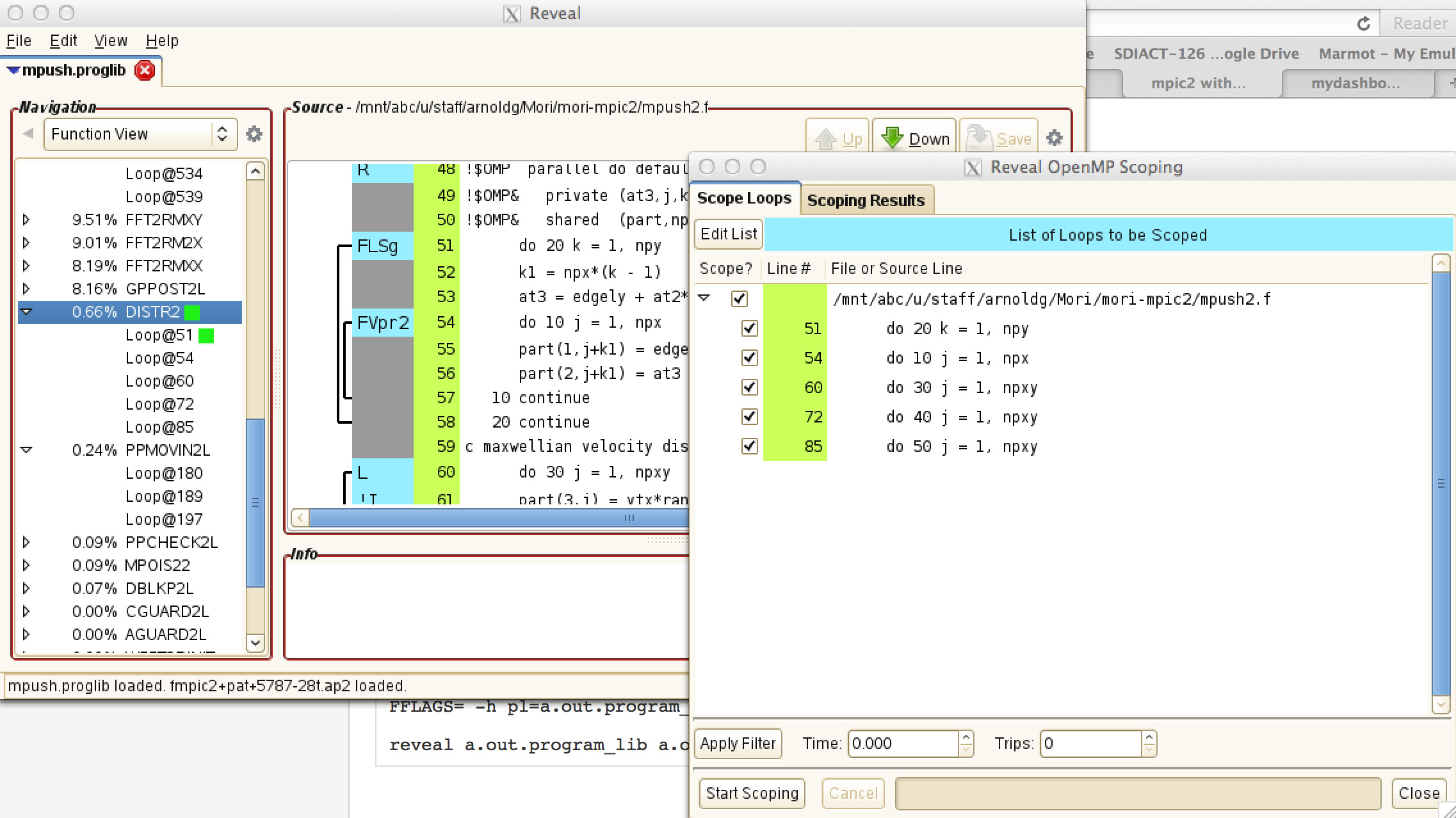
Right click on the function or loop of interest and you'll be presented with the option to "Scope Loop". If a function was selected, all of its loops will be automatically selected. The Reveal OpenMP Scoping tool is not fully-automatic. Some degree of programmer steering is needed to get sensible results (if you let it scope all loops, you'll end up with an impossible set of directives and the compiler will throw errors later when it discovers you're trying to thread inner and outer loops simultaneously).
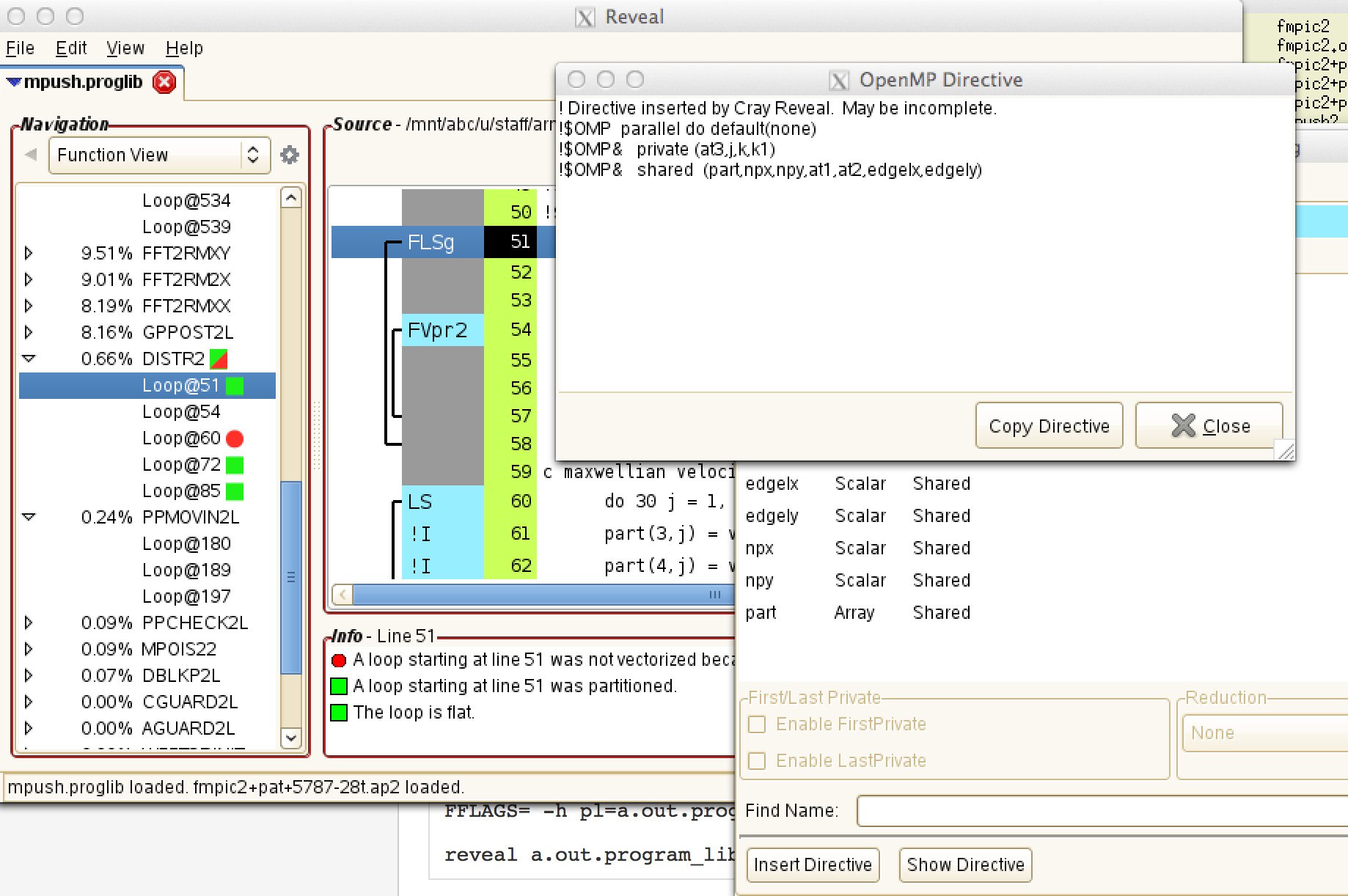
After scoping a loop, you'll see a dialog appear with the variable scopes and options to Insert or Display the OpenMP directives. Display will show the suggested directives without code modification and insert will change the source code which you may later save.
Results of OpenMP code additions from Cray Reveal With the stock unmodified kernel for this code (already marked for OpenMP on the most compute intensive loops), here are the timings: aprun -n 1 -d16 ./a.out ... deposit time = 1.66461015 ... push time = 2.34570265 ... Total Particle Time (nsec) = 8.77031326 After adding a couple of the directives suggested by Cray Reveal for loops that were still marked as hot in the loop view:
apun -n 1 -d16 ./a.out Here are the code changes deployed that yielded the performance improvement above:
Additional Information / References |
Skip to Content



Blue Waters User Portal
Sign In

Blue Waters is supported by the National Science Foundation (awards OCI-0725070 and ACI-1238993) the State of Illinois, and the National Geospatial-Intelligence Agency.
Contact Blue Waters Team with questions regarding this page.
Copyright 2024 Board of Trustees of the University of Illinois. All rights reserved. Web privacy notice.