Overlapping Computation & Communication with MPI Non-blocking Calls
Enable MPI shared memory optimizations
Link with DMAPP library with following link flags
Static linking:
Dynamic linking: Enable optimized DMAPP collectives
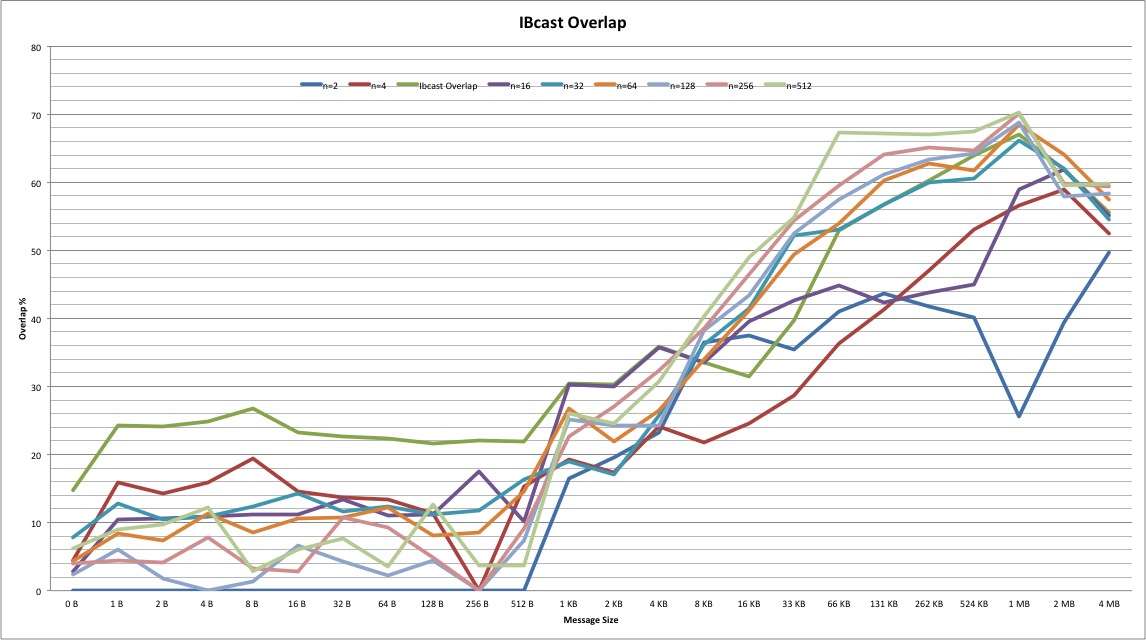
Results: The following results show overlap % for various message sizes and rank count
|
Skip to Content



Blue Waters User Portal
Sign In

Blue Waters is supported by the National Science Foundation (awards OCI-0725070 and ACI-1238993) the State of Illinois, and the National Geospatial-Intelligence Agency.
Contact Blue Waters Team with questions regarding this page.
Copyright 2024 Board of Trustees of the University of Illinois. All rights reserved. Web privacy notice.